


Coding and web scraping may seem like a daunting task if you’re unfamiliar or new to the concept of computer code in general. In reality, they are not nearly as complicated to understand as you’re probably thinking.
When it comes to web scraping with any programming language, the process ultimately boils down to the three core steps.
- Build your base by choosing your desired programming language.
- Find your target website.
- Find the data you want to scrape from said website.
If you take each of these steps in order, you’ll be able to scrape data from any website with ease, and this beginner’s guide will cover each step in detail so you can start web scraping yourself.
Get Setup
Start by gathering all the tools that you’re going to need for web scraping. For beginners, this will include two primary tools, which are a coding language and a library.
What Programming Language Should I Learn?
There are many programming languages that you can find with a simple web search, and most of them are perfectly fine to use. However, for this guide, we will be using Python to perform web scraping.
Python offers a level of accessibility that makes it easy for beginners and first-time coders to try their hands at web scraping. On top of that, Python provides a deep level of flexibility that makes it an excellent choice for coders who are more experienced and need a wide array of tools to work with.
Additionally, if you want to learn to code, Python is the best programming language because it is so accessible, and people have already developed many guides and tutorials for it.
You can get started learning Python by using the official tutorial, but do note that it is not a comprehensive tutorial. It aims to cover as many of Python’s features as possible.
Because of that, it is better to read over some of the more general topics in that tutorial and then some entry-level tutorials to coding as a whole.
Adding on The Beautiful Soup Library
While the Python programming language is great on its own, you will need a library like Beautiful Soup to sort through all the information you’re going to be scraping.
You can do web scraping without a library, but utilizing one is still heavily recommended since it will save you more than a few hours of quality work.
Starting The Web Scraping Process
Now let’s cover the actual step-by-step process for how to find large amounts of data by web scraping.
Decide What Website You Want to Scrape for Data
The first step in the web scraping process involves identifying what website we want to scrape for information.
There is no actual limit or restrictions to what website you can choose to scrape for data. However, not all websites allow web scraping, and scraping a website that does not allow it can result in legal issues.
Pinpoint the Data You’re Looking For
To scrape a website for data, go to your website of choice and right-click the page itself, then go down to the bottom of the menu that pops up and select “Inspect.”
After clicking on “Inspect,” you will see a console appear and take up about a quarter of the right side of your screen like this.
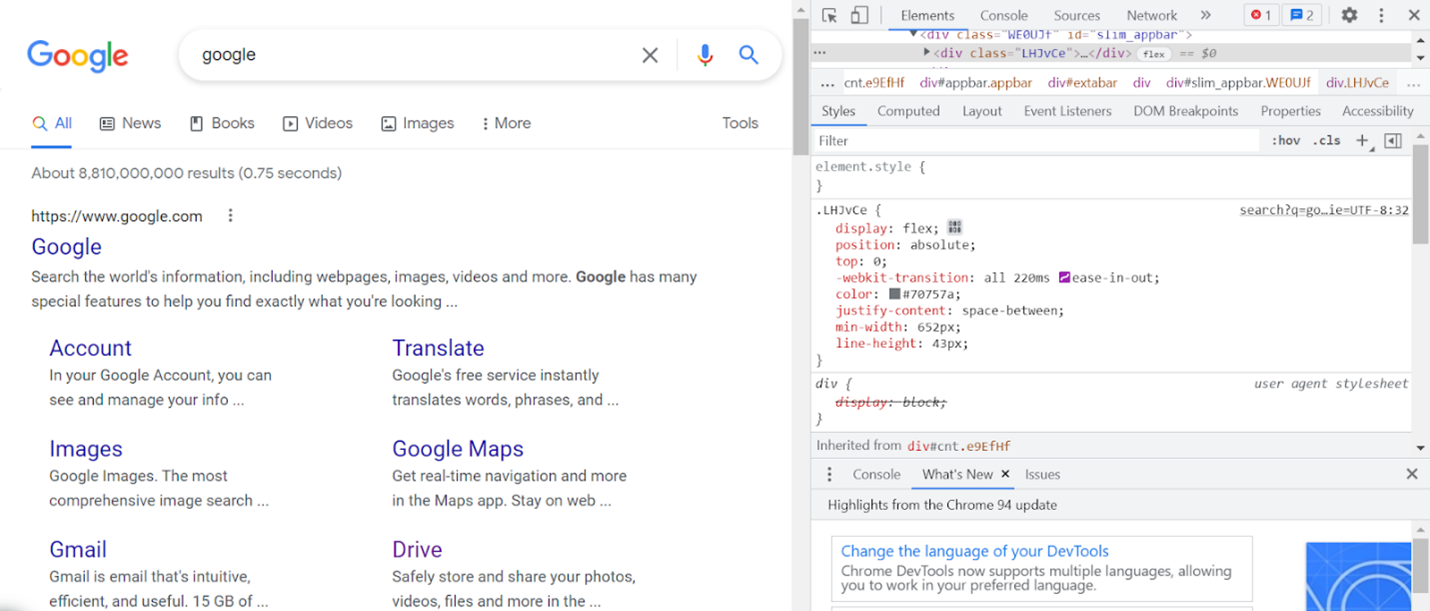
Here you can look directly at the coding itself.
Next, go to the top left corner of the console and select the small arrow/box icon that looks like this.
![]()
By doing this, you will be able to hover your cursor over any of the text, images, or other icons on the website page and see the specific code for each individual piece of the page. Use this method to find one instance of the specific data that you desire.
Create the Python File for Your Data
Once you know what data you want to scrape, go ahead and create a Python file, give it a name, and import the Beautiful Soup library.
To import Beautiful Soup, type “from bs4 import BeautifulSoup” into your Python file.
Next, you’ll need code to interact with the URL of your chosen website.
To set this up, type these three commands into your Python file, “import urllib.request”, “import requests,” “import time.”
These four commands will act as the base for your web scraping, and you can utilize them to access the URL of any site.
Access and Start Scraping Data
To access the URL for the website you wish to scrape, type “url = ‘paste the url here,’ into your Python file, then beneath this line type, ‘response = request.get(url)’.
Once the request for access goes through, you can use the Beautiful Soup library you imported earlier to parse the HTML and round up all the desired information with the ‘find all’ command.
Into your Python file, type “soup = BeautifulSoup (response.text, “html.parser”),” followed by “soup.findall (‘type whatever the desired data tag is here’)”.
More often than not, whatever group of data you’re looking for will fall under one tag. So, for example, if you find one piece of the data you want and it is under the tag , you would type “soup.findall (‘a’)”.
That command will bring you every piece of data with that specific tag and effectively scrape all of that type of data up at once.
If you want to scrape different sets of data that all have their own tags, repeat the above process for each data set until you have found all the ones you want.
Conclusion
Coding and web scraping do require some work to really get into and deeply understand the nitty-gritty aspects, but you only need to gain some semblance of understanding to get started. From there, it’s all about practice and repetition, so don’t be discouraged if parts of this guide seem less ‘beginner-friendly.’
Just be patient and keep everything we’ve discussed here in mind as you further practice and learn about the utility of web scraping!
Author’s Bio
Christoph Leitner’s bio
Bulleted
- full-stack developer at zenscrape.com, a subsidiary of saas.industries
- marathon runner
- father of two children
Christoph is a code-loving father of two beautiful children. He is a full-stack developer and a committed team member at Zenscrape.com - a subsidiary of saas.industries. When he isn’t building software, Christoph can be found spending time with his family or training for his next marathon.